Juan's RLAC Notes
For this exercise, I used my actual human language reading and listening skills for the first time in the class [in order to evaluate the accuracy, pitfalls, and internal biases of a Speech to Text algorithm when exposed to English speakers of different origins, accents, cadences, and levels of fluency. To achieve this, I closely listened to a 15-minute segment of a Rooftop Rhythms spoken word poetry event and compared it with its transcript generated automatically by Kaltura (NYU Stream)’s algorithm.
I chose a 15-minute segment from the September 2019 Rooftop Rhythms episode for two reasons. First, it was one of the last Rooftop Rhythms events recorded with a live audience, allowing me to examine the impact of background sound, crowd noise and clapping in the algorithm’s accuracy. Second, the segment I chose features seven different speakers of apparently different origins, two of them considered people of determination, allowing me to examine the biases of the algorithm against the particularities of each of the performers.
The first performers in the segment are a woman with an American accent and a man of determination. This performance is very useful to test the STT algorithm as it consists of the woman and the man repeating the exact same words. The algorithm performed well on the woman’s segments, however didn’t recognise most of those of the man as speech, even if to me they were more than perfectly intelligible. This could be used to hypothesise two things: that the model is not trained with this kind of speech or that, because the man’s speech was lower than the woman’s, the algorithm filtered it out as noise.

In each segment, the first line corresponds to the woman and the second to the man of determination. Notice the differences in what are supposed to be the same words.
The second performance was too of a woman and a man of determination. However, their performance experimented with exaggerated voices and registers other than the standard, and they also mentioned proper names in Arabic. Part of the performance also included the speakers speaking at the same time, which could have made it even more difficult for the STT algorithm. Unsurprisingly, the transcription generated not more than a couple of lines of text from a 3-minute performance, sometimes not even recognising entire sections as speech.
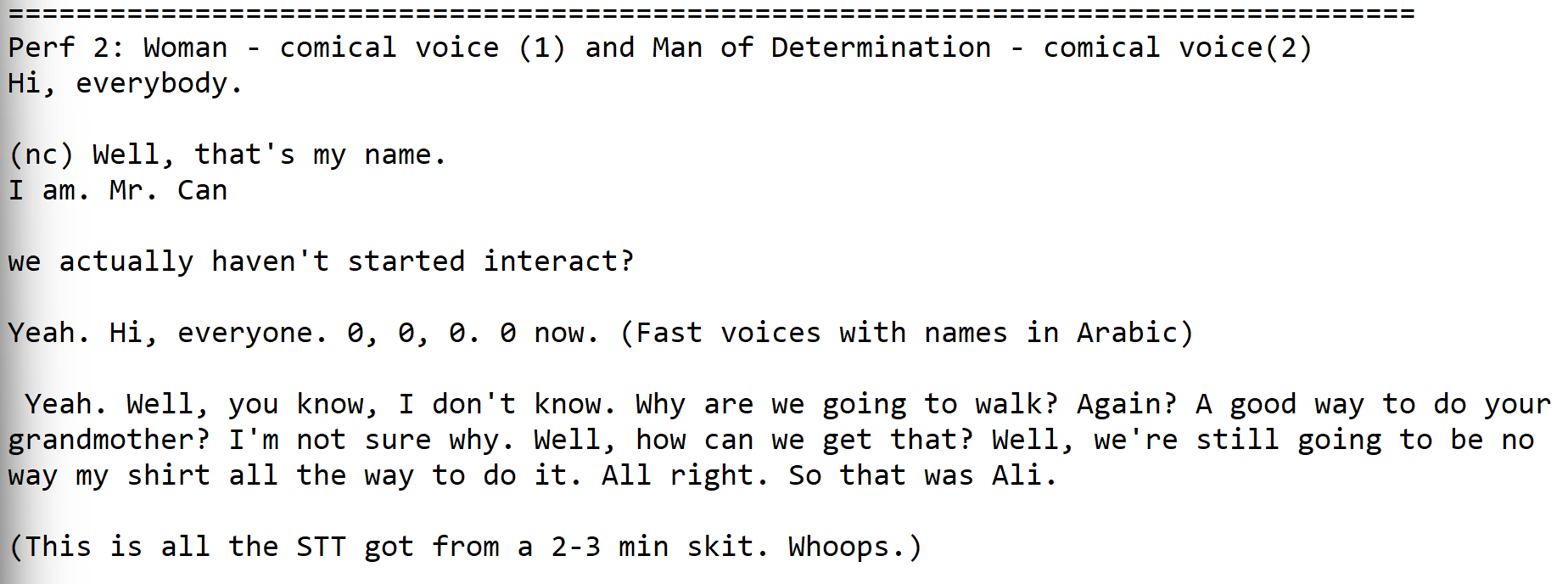
This segment is all the transcription for three minutes of performance.
The third performance is of a man that varies between a standard register and different voices in order to structure his poem. The first part of the poem is delivered in an elicited, fast pace, and is therefore inaccurately transcribed by the algorithm. However, as his register normalises and his pace slows down, the transcription starts showing very high levels of accuracy. The man stutters and pauses once during the performance, but the transcription seems designed to approximate his stutters to the closest full word. The algorithm deals well with moderate-speed speech, but not with cut words or fast speech.
The fourth speaker is Dorian Rogers, the host of the show. Most of his intervention is accompanied by claps and other background noises, which makes the algorithm not recognise any of it as speech. As well, Dorian uses many contractions and expressions that the algorithm cannot recognise, and speaks at a speed that reduces its accuracy. However, he stops to recite a line of poetry, which he does in a standard register and is transcribed accurately.

Notice how the line of poetry (center) makes more sense than the other text.
The fourth and last performance of this segment is of a woman reciting a slam poem. As in the other performances, although the STT transcription is highly accurate when her pace is moderate, the transcription starts to fail when the cadence increases and the pauses between words disappear. As well, she uses homophones and words with repeated sounds as a stylistic device, and this seems to affect the accuracy of the transcription. Her performance is more closely related to the conventions of slam poetry, which often uses devices and grammatical structures not usually associated with “standard English”, which results in the transcription biasing itself to produce grammatically standard sentences and resulting in an inaccurate result

Comparison of the "standard English" of the transcription and the colloquial grammar of the poem.

A sample sentence with homophones
In short, we can infer the algorithm was trained on standard English with a medium cadence, and there is a pattern of misrecognition of vernacular constructions, background sound, differences in volume, and different voice registers. This could be due to the fact that, as a general purpose algorithm, it was trained on large amounts of readily available materials, such as newscasts and radio transmissions from the richest English-speaking countries. This training, however, means that the transcriptions generated as a result of it restrict the boundaries of “standard English”, and invisibilises diverse practices of language. In a world where transcriptions are used for text processing, search engine optimisation and mass data collection, this restriction compounds to a disadvantage to speakers of other varieties of English.
ready for grading - dec 7th, 2021